
Validity vs Reliability: Differences, Examples & How to Improve


Validity and reliability are the two pillars of measurement quality in research. A study can collect thousands of data points, but if the measurement tools are not valid (measuring what they claim to measure) or not reliable (producing consistent results), the findings are fundamentally untrustworthy. A 2025 analysis in Advances in Methods and Practices in Psychological Science found a statistically aberrant clustering of Cronbach's alpha values at exactly .70, the commonly cited minimum threshold, suggesting that researchers may be manipulating or selectively reporting reliability results to meet this benchmark rather than genuinely achieving it. [1]
The consequences of poor measurement quality extend far beyond individual studies. The reproducibility crisis, which affects an estimated 70% of published research across disciplines, is driven in large part by inadequate attention to validity and reliability during the design phase. When measurements lack validity, up to 50% of research conclusions can be misleading or incorrect. When measurements lack reliability, findings cannot be replicated even under identical conditions. [2]
This guide explains the difference between validity and reliability, covers all major types of each, provides examples across disciplines, identifies common mistakes, and offers a step-by-step process for improving both in your research design.
Key Takeaways

- Validity measures whether a tool actually measures what it claims to measure. Reliability measures whether it produces consistent results.
- A measurement can be reliable without being valid, but it cannot be valid without being reliable.
- The reproducibility crisis affects approximately 70% of published research, with measurement quality as a key contributing factor. [2]
- A 2025 study found suspicious clustering of Cronbach's alpha values at exactly .70, raising concerns about selective reliability reporting. [1]
- The four main types of validity are content, construct, criterion, and internal validity. The three main types of reliability are test-retest, inter-rater, and internal consistency.
- Use the checklist and improvement strategies in this guide to strengthen both validity and reliability before data collection.

What Is Validity in Research?
Validity refers to the degree to which a measurement tool, test, or instrument actually measures what it is intended to measure. A valid measurement captures the true concept under investigation rather than something else entirely.
Example: A survey designed to measure "job satisfaction" is valid if it actually captures how satisfied employees are with their jobs. If the survey primarily asks about salary but ignores factors like autonomy, relationships, and growth opportunities, it may not be a valid measure of overall job satisfaction.
Validity is not binary (valid or invalid). It exists on a spectrum, and researchers must provide evidence that their measurements are sufficiently valid for the specific context and purpose of their study.
Types of Validity
Content Validity evaluates whether the measurement covers all aspects of the construct it claims to measure. It is typically assessed through expert review. If a final exam in a statistics course only tests material from the first three weeks and ignores the remaining ten weeks, it lacks content validity.
Construct Validity evaluates whether the measurement accurately reflects the theoretical construct it is designed to assess. It includes convergent validity (the measure correlates with related constructs) and discriminant validity (the measure does not correlate with unrelated constructs). If a depression scale also measures anxiety equally well, its discriminant validity is questionable.
Criterion Validity evaluates whether the measurement correlates with an external criterion or outcome. It includes concurrent validity (correlation with a current criterion) and predictive validity (correlation with a future outcome). A college admissions test has predictive validity if high scores predict strong academic performance.
Internal Validity evaluates whether the study design allows the researcher to confidently attribute observed effects to the independent variable rather than confounding factors. In experimental research, internal validity is compromised when uncontrolled variables could explain the results.
A 2025 analysis examining one decade of post-replication-crisis research found that while effect sizes in psychology have decreased since the crisis, measurement practices and construct validity reporting remain inconsistent across studies, suggesting that the field has not fully addressed the root causes of irreproducibility. [3]
What Is Reliability in Research?
Reliability refers to the degree to which a measurement tool produces consistent, stable results when used under the same conditions. A reliable instrument yields the same or very similar results each time it is applied to the same population or phenomenon.
Example: A bathroom scale is reliable if it shows the same weight every time you step on it within a short period. If it shows 70 kg, then 73 kg, then 68 kg in three consecutive measurements, it is unreliable.
Like validity, reliability is assessed through specific methods and reported as a numerical coefficient.
Types of Reliability
Test-Retest Reliability measures the consistency of results when the same test is administered to the same group at two different points in time. It is reported as a correlation coefficient (typically Pearson's r). A coefficient above 0.80 is generally considered acceptable for established instruments.
Example: A personality questionnaire administered to 200 participants today and again in two weeks produces a test-retest correlation of r = 0.87, indicating good stability over time.
Inter-Rater Reliability measures the degree of agreement between two or more independent raters or observers evaluating the same phenomenon. It is commonly reported using Cohen's kappa (for two raters) or intraclass correlation coefficient (ICC) for multiple raters. A 2025 review in BMC Medical Research Methodology emphasized that many published studies fail to report adequate inter-rater reliability details, including the number of raters, training procedures, and the specific agreement statistic used, making it difficult to assess the quality of the measurements. [4]
Example: Two clinicians independently assess 50 patient X-rays for the presence of a fracture. If they agree on 47 out of 50 cases, inter-rater reliability is high.
Internal Consistency measures whether multiple items on a test that are supposed to measure the same construct produce similar scores. It is most commonly reported using Cronbach's alpha, where values above 0.70 are traditionally considered acceptable for research purposes and above 0.90 for clinical applications.
Example: A 20-item anxiety scale has a Cronbach's alpha of 0.89, indicating that the items consistently measure the same underlying construct.
However, the .70 threshold has come under scrutiny. Hussey et al. (2025) found that an implausible number of published studies report Cronbach's alpha values at exactly .70, suggesting selective item deletion, selective reporting, or rounding to meet the threshold rather than genuine reliability. [1]
Validity vs Reliability: Key Differences
Understanding how validity and reliability relate to each other is critical for evaluating any measurement in research.
| Criteria | Validity | Reliability |
|---|---|---|
| Definition | Measures what it claims to measure | Produces consistent results |
| Focus | Accuracy of the measurement | Consistency of the measurement |
| Can exist alone? | No — requires reliability first | Yes — can be reliable but not valid |
| Assessment methods | Expert review, correlation, factor analysis | Test-retest, inter-rater, Cronbach's alpha |
| Reported as | Evidence arguments, correlation coefficients | Reliability coefficients (r, alpha, kappa) |
| Threat if absent | Measuring the wrong construct entirely | Results fluctuate unpredictably |
| Key question | Am I measuring the right thing? | Am I measuring it consistently? |
The most important relationship to understand: a measurement can be reliable without being valid, but it cannot be valid without being reliable. If a scale consistently gives the wrong weight (always 5 kg too high), it is reliable but not valid. If a scale gives a different reading every time, it is neither reliable nor valid, and therefore cannot be valid.
This means reliability is a necessary but not sufficient condition for validity. Establishing reliability is always the first step, but it does not guarantee that the instrument is measuring the correct construct.

How to Assess Validity and Reliability (Step-by-Step)
Follow this process to evaluate and establish both validity and reliability for your measurement instruments.
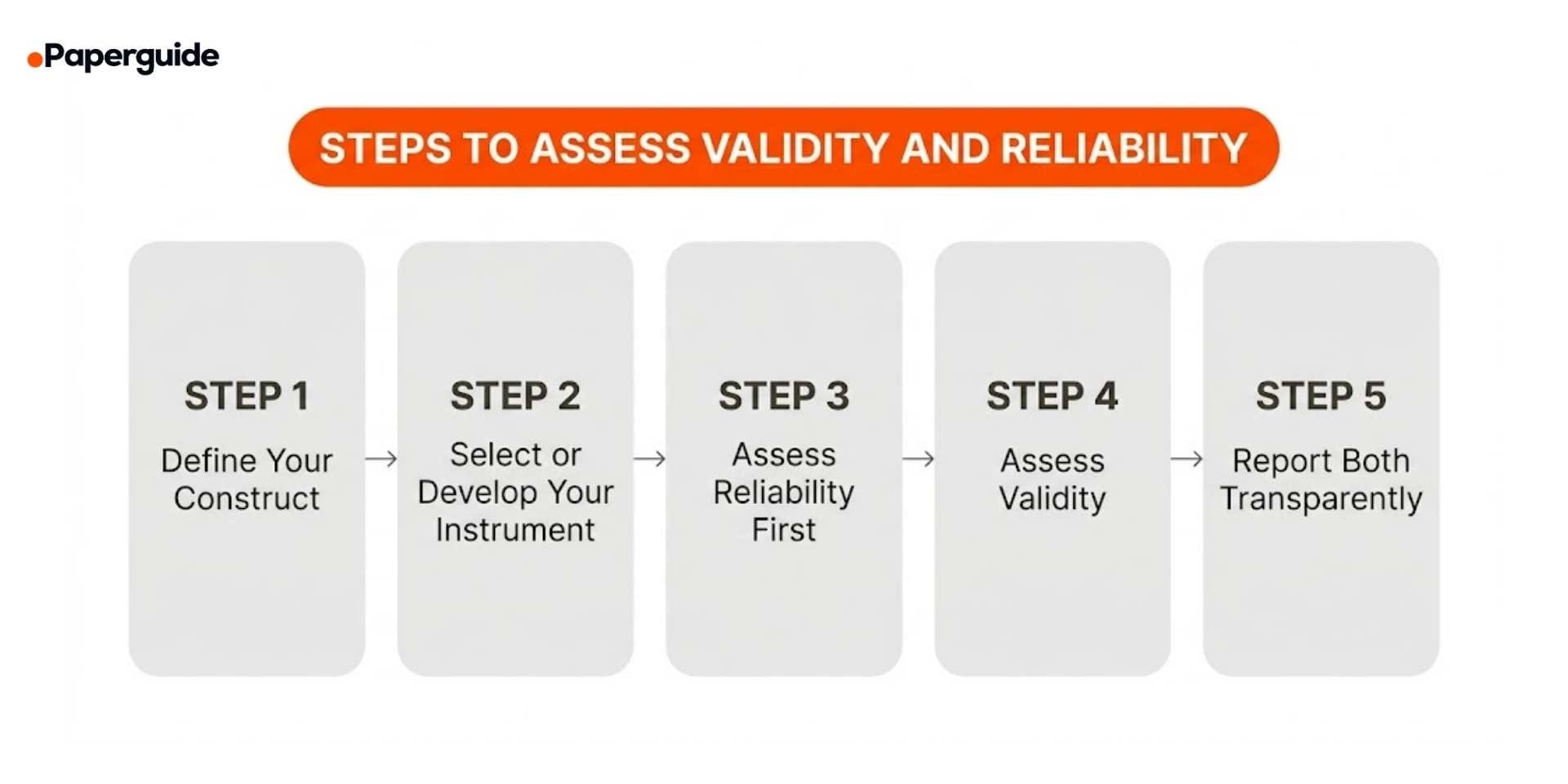
Step 1: Define Your Construct Clearly
Before selecting or designing a measurement instrument, define exactly what you are trying to measure. A vague construct leads to vague measurement.
Example: Instead of measuring "student engagement," define whether you mean behavioral engagement (attendance, participation), cognitive engagement (effort, strategy use), or emotional engagement (interest, belonging). Each requires a different measurement approach.
Step 2: Select or Develop Your Instrument
Whenever possible, use established, validated instruments from published literature rather than creating new ones. Existing instruments already have documented reliability and validity evidence.
If you must develop a new instrument, base it on a thorough literature review and have it reviewed by subject matter experts (to establish content validity) before piloting it.
Step 3: Assess Reliability First
Since reliability is a prerequisite for validity, test it first:
- Internal consistency: Calculate Cronbach's alpha during pilot testing. Values of .70 or above are generally acceptable for research, but consider the context and do not manipulate items solely to reach this threshold.
- Test-retest: Administer the instrument twice to the same group with an appropriate time interval (typically two to four weeks). Calculate the correlation between scores.
- Inter-rater: If your measurement involves subjective judgment (e.g., coding qualitative data, rating behaviors), train raters and calculate agreement using Cohen's kappa or ICC.
Step 4: Assess Validity
Once reliability is established, assess validity through multiple approaches:
- Content validity: Have three or more subject matter experts review the instrument and rate whether each item adequately represents the construct. Agreement above 80% indicates acceptable content validity.
- Construct validity: Use factor analysis to confirm that items load onto the expected dimensions. Test convergent validity (correlation with related measures) and discriminant validity (low correlation with unrelated measures).
- Criterion validity: Correlate scores on your instrument with an established criterion measure or outcome.
Step 5: Report Both Transparently
Report all reliability and validity evidence in your methodology section, including specific coefficients, sample sizes, and any limitations. Transparent reporting allows readers and reviewers to evaluate your measurement quality independently. Researchers working across multiple studies benefit from using AI tools for academic writing that help structure methodology sections consistently and ensure all required measurement details are included.
Examples Across Disciplines
Example 1: Psychology
Instrument: Beck Depression Inventory (BDI-II)
- Reliability: Internal consistency (Cronbach's alpha = .91). Test-retest reliability over one week (r = .93).
- Validity: Content validity established through expert clinician review. Construct validity supported by high correlation with the Hamilton Depression Rating Scale (convergent) and low correlation with measures of unrelated constructs like physical fitness (discriminant). Criterion validity demonstrated by correlation with clinical diagnosis.
Example 2: Education
Instrument: End-of-semester course evaluation survey
- Reliability: Internal consistency (Cronbach's alpha = .84) across 15 items measuring teaching effectiveness.
- Validity: Content validity reviewed by an instructional design committee. However, construct validity may be questionable if students rate based on grade expectations rather than actual teaching quality (a known validity threat in course evaluations).
Example 3: Public Health
Instrument: Self-reported physical activity questionnaire
- Reliability: Test-retest reliability over two weeks (r = .78). Acceptable but indicates some variability, possibly due to genuine changes in activity levels between administrations.
- Validity: Criterion validity assessed by comparing self-reported activity with accelerometer data. Moderate correlation (r = .45) suggests the questionnaire captures the general trend but overestimates actual activity levels.
Example 4: Business
Instrument: Employee engagement survey (12-item scale)
- Reliability: Internal consistency (Cronbach's alpha = .88). Inter-rater reliability not applicable (self-report measure).
- Validity: Construct validity supported by factor analysis confirming three subscales (vigor, dedication, absorption). Predictive validity demonstrated by correlation with employee retention rates over 12 months (r = .41).
Each example illustrates that validity and reliability are assessed using different methods depending on the instrument type, research context, and available criterion measures.
How to Improve Validity and Reliability
Improving measurement quality is an active process that should begin during the design phase and continue through data collection. Below are specific strategies for each.
Improving Validity
Use established, validated instruments. Whenever a well-validated instrument exists for your construct, use it rather than developing a new one. Modifications to validated instruments (such as removing or rewording items) require re-validation.
Conduct expert review. Have three to five subject matter experts evaluate your instrument for content coverage, clarity, and relevance. Revise items that receive low ratings.
Pilot test with your target population. Administer the instrument to a small sample from your intended population. Analyze whether participants interpret items as intended through cognitive interviews or think-aloud protocols.
Use multiple measures. Measure the same construct using two or more methods (e.g., self-report questionnaire plus behavioral observation). Agreement across methods strengthens construct validity through triangulation.
Control for threats to internal validity. In experimental designs, use random assignment, blinding, and standardized procedures to minimize confounding variables that could threaten the validity of causal conclusions.
Improving Reliability
Increase the number of items. Longer instruments tend to have higher internal consistency, up to a point. Adding well-designed items that measure the same construct can improve Cronbach's alpha.
Standardize administration procedures. Ensure every participant receives the same instructions, conditions, and time limits. Variability in administration introduces error that reduces reliability.
Train raters thoroughly. For observational or coding measures, provide detailed scoring rubrics, conduct calibration sessions, and calculate inter-rater reliability before beginning data collection. Address disagreements through discussion and re-calibration.
Remove ambiguous items. During pilot testing, identify items with low item-total correlations (below .30) or items that participants frequently misinterpret. Revise or remove them.
Use appropriate time intervals for test-retest. Choose a time interval long enough to prevent memory effects but short enough that the construct itself has not genuinely changed. Two to four weeks is typical for most psychological and educational measures.
Strengthening both validity and reliability early in the research process prevents downstream problems that no amount of statistical analysis can fix. Exploring best AI paper writing tools can help researchers structure their methodology sections to clearly document measurement quality decisions.
Common Mistakes and How to Fix Them
Measurement errors related to validity and reliability are among the most frequent and most damaging methodological problems in published research. [5]

Mistake 1: Assuming Reliability Equals Validity
Error: Reporting a high Cronbach's alpha and concluding that the instrument is therefore valid.
Fix: Reliability is necessary but not sufficient for validity. A reliable instrument may consistently measure the wrong thing. Always provide separate validity evidence (content, construct, criterion) alongside reliability data.
Mistake 2: Skipping Pilot Testing
Error: Deploying a measurement instrument for the first time on the full study sample without any prior testing.
Fix: Always pilot test your instrument with a small sample (typically 20 to 50 participants) from your target population. Use the pilot data to calculate preliminary reliability, identify problematic items, and confirm that participants interpret questions as intended.
Mistake 3: Manipulating Items to Reach Alpha .70
Error: Deleting items from a scale solely because removing them increases Cronbach's alpha to the .70 threshold, without considering whether the removed items are conceptually important.
Fix: Evaluate items based on both statistical performance (item-total correlation) and conceptual importance. If an item is essential to the construct but has a low item-total correlation, revise the wording rather than deleting it. Report your decision-making process transparently. [1]
Mistake 4: Using Unvalidated Instruments
Error: Creating a new questionnaire or measurement tool for a study without providing any validity evidence.
Fix: If no validated instrument exists, develop your tool systematically: define the construct, generate items based on literature, conduct expert review (content validity), pilot test, perform factor analysis (construct validity), and correlate with a criterion measure if one exists.
Mistake 5: Ignoring Population and Context Differences
Error: Using an instrument validated in one population (e.g., American college students) for a different population (e.g., elderly adults in rural Japan) without re-examining validity.
Fix: Re-assess validity whenever using an instrument in a new context, population, or language. At minimum, conduct a pilot test and recalculate reliability. Ideally, re-examine construct validity through confirmatory factor analysis.
Mistake 6: Not Reporting Measurement Quality
Error: Failing to include specific reliability coefficients, validity evidence, and measurement details in the published methodology.
Fix: Report all relevant coefficients (Cronbach's alpha, test-retest r, kappa, ICC) with sample sizes. Describe how validity was assessed. Include this information in the methodology section, not as supplementary material.
Validity and Reliability Checklist
Use this checklist to verify your measurement quality before finalizing your research design.
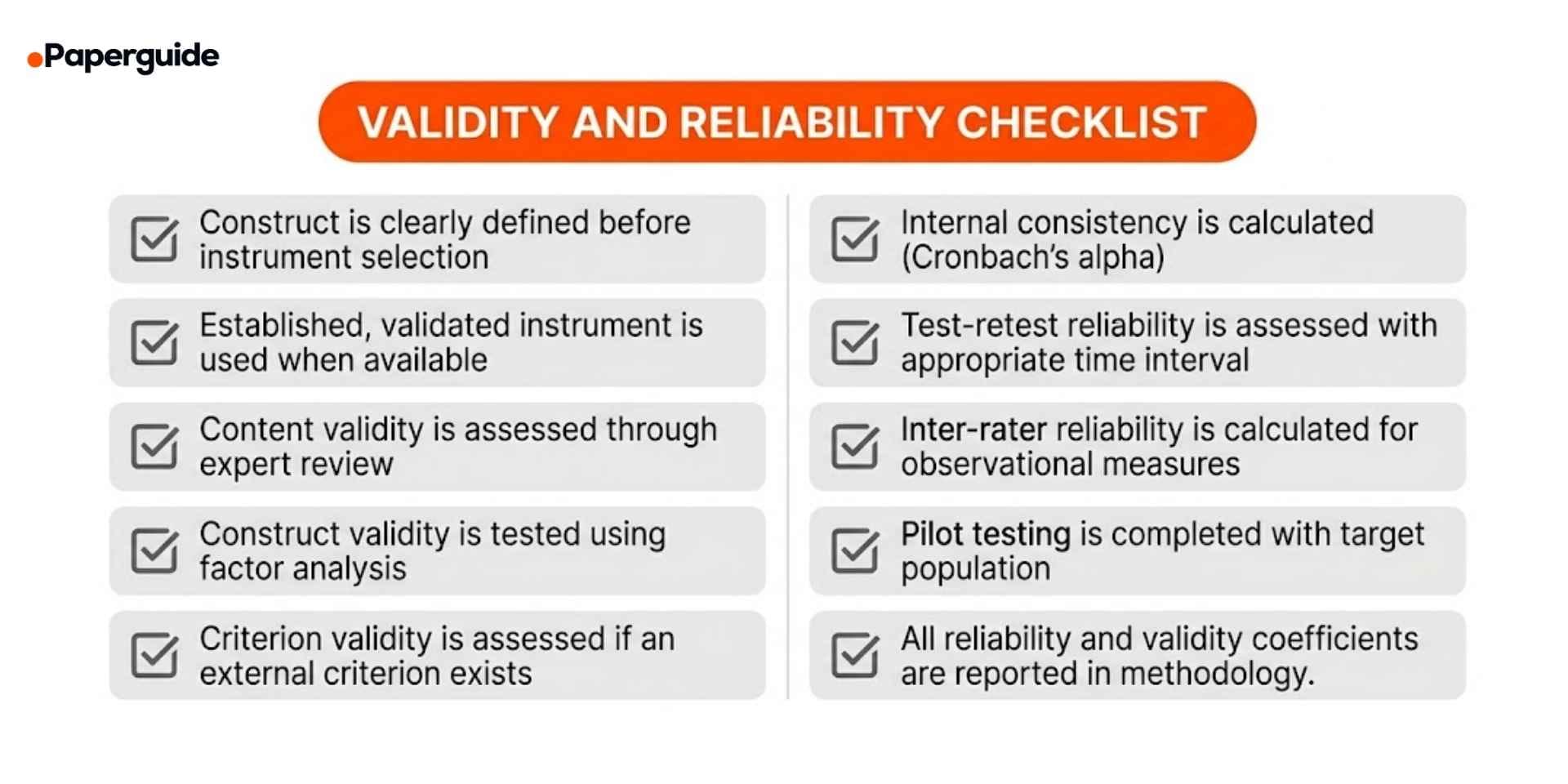
- [ ] Construct is clearly defined before instrument selection. You can describe exactly what you are measuring and why.
- [ ] Established, validated instrument is used when available. If a well-validated tool exists, you have adopted it rather than creating a new one.
- [ ] Content validity is assessed through expert review. Three or more experts have reviewed the instrument for coverage and relevance.
- [ ] Construct validity is tested using factor analysis. Items load onto the expected dimensions, with convergent and discriminant validity assessed.
- [ ] Criterion validity is assessed if an external criterion exists. Scores correlate with an independent criterion measure or outcome.
- [ ] Internal consistency is calculated. Cronbach's alpha (or an appropriate alternative) is reported for multi-item scales.
- [ ] Test-retest reliability is assessed with appropriate time interval. The instrument produces stable results over a suitable time period.
- [ ] Inter-rater reliability is calculated for observational measures. Raters are trained and agreement is quantified before data collection.
- [ ] Pilot testing is completed with target population. The instrument has been tested on a representative small sample before full deployment.
- [ ] All reliability and validity coefficients are reported in methodology. Specific numbers, sample sizes, and assessment methods are documented.
Measurement Quality Template
Use this template to document the validity and reliability of your measurement instruments. Replace the bracketed sections with your own content.
Construct Being Measured: [Exactly what you are measuring]
Instrument: [Name of instrument or tool] Source: [Published source or "developed for this study"]
Reliability Evidence: Internal consistency: [Cronbach's alpha value and sample size] Test-retest: [Correlation coefficient, time interval, and sample size] Inter-rater: [Agreement statistic, number of raters, and training description]
Validity Evidence: Content validity: [Number of expert reviewers and agreement level] Construct validity: [Factor analysis results, convergent/discriminant evidence] Criterion validity: [Correlation with criterion measure, if applicable]
Known Limitations: [Any acknowledged measurement weaknesses]
Filled Example:
Construct Being Measured: Academic self-efficacy in undergraduate STEM students
Instrument: Academic Self-Efficacy Scale (ASES), 24-item version Source: Chemers et al. (2001), adapted for STEM context
Reliability Evidence: Internal consistency: Cronbach's alpha = .91 (n = 312) Test-retest: r = .84 over three weeks (n = 85 subsample) Inter-rater: Not applicable (self-report measure)
Validity Evidence: Content validity: Reviewed by four STEM education researchers; 92% item agreement Construct validity: Confirmatory factor analysis supported the three-factor structure (mastery experience, vicarious experience, social persuasion). Convergent validity: r = .67 with General Self-Efficacy Scale. Discriminant validity: r = .21 with Social Desirability Scale. Criterion validity: Predictive validity: r = .38 with end-of-semester GPA
Known Limitations: Self-report measure subject to social desirability bias. Adapted version has not been validated outside the US context.
Validate This With Papers (2 Minutes)
Before finalizing your measurement instruments, check how published studies in your field have assessed validity and reliability for similar constructs. This prevents using instruments with known weaknesses and strengthens your methodology.
Step 1: Search for recent studies that measured the same or a similar construct to yours. Focus on how they describe instrument selection, validation, and reliability testing in their methodology sections.
Step 2: Open two or three relevant papers. Look at which instruments they used, what reliability coefficients they reported, and how they assessed validity. Reviewing AI tools for systematic review can help you efficiently compare measurement approaches across multiple studies in your field.
Step 3: Use an Article Summarizer to extract the methodology section from each paper. Compare their instrument choices, reported coefficients, and acknowledged measurement limitations with yours.
This takes about two minutes and ensures your measurement approach is consistent with current best practices in your discipline.
Conclusion
Validity and reliability are not optional quality checks, they are the foundation that determines whether research findings are meaningful and reproducible. Validity ensures you are measuring the right construct, and reliability ensures you are measuring it consistently. Without both, no amount of data or sophisticated analysis can produce trustworthy conclusions. The step-by-step process in this guide, define your construct, select or develop your instrument, assess reliability first, then validity, and report both transparently, provides a systematic approach to building measurement quality into your research design from the start.
The most damaging measurement errors are also the most preventable. Skipping pilot testing, using unvalidated instruments, manipulating items to reach reliability thresholds, and failing to report measurement details are problems that undermine entire studies. Before collecting any data, verify your instrument against the checklist above, compare your measurement approach with published studies in your field, and document every validity and reliability decision in your methodology section. Strong measurement is not a formality; it is the difference between research that contributes to knowledge and research that adds to the reproducibility crisis.
Frequently Asked Questions
What is the difference between validity and reliability?
Validity refers to whether a measurement tool actually measures what it claims to measure (accuracy). Reliability refers to whether it produces consistent results across repeated applications (consistency). A measurement can be reliable without being valid, but it cannot be valid without first being reliable.
Can a test be reliable but not valid?
Yes. A scale that consistently measures 5 kg too heavy is reliable (consistent results) but not valid (inaccurate). In research, a survey might consistently measure a construct, but if that construct is not what the researcher intended to measure, the instrument is reliable but not valid.
What is Cronbach's alpha and what value is acceptable?
Cronbach's alpha measures internal consistency — the degree to which items on a scale measure the same construct. Values above .70 are traditionally considered acceptable for research, and above .90 for clinical applications. However, the .70 threshold has been criticized for being applied too rigidly, and researchers should consider context rather than treating it as a universal pass/fail cutoff.
How do I know if my instrument is valid?
Validity is established through multiple types of evidence: content validity (expert review of item coverage), construct validity (factor analysis, convergent and discriminant correlations), and criterion validity (correlation with an external outcome). No single test proves validityit is an accumulation of evidence supporting that the instrument measures what it claims.
What is the most common type of reliability reported?
Internal consistency (Cronbach's alpha) is the most frequently reported reliability measure because it can be calculated from a single administration of the instrument. However, test-retest reliability and inter-rater reliability provide additional and sometimes more important evidence depending on the measurement context.
Should I assess validity or reliability first?
Assess reliability first. Since reliability is a necessary condition for validity, there is no point in validating an instrument that produces inconsistent results. Establish acceptable reliability, then proceed to validity assessment.
How often should reliability be reassessed?
Reliability should be reassessed whenever an instrument is used with a new population, in a new context, or after any modifications have been made. Even well-established instruments should have their reliability reported for each new study sample.
What is the relationship between validity, reliability, and the reproducibility crisis?
Poor validity means studies may be measuring the wrong constructs, leading to conclusions that do not hold when tested differently. Poor reliability means studies produce inconsistent results, making replication unlikely. Both contribute significantly to the estimated 70% of published research affected by reproducibility concerns.
References
- Hussey, I. et al. "An Aberrant Abundance of Cronbach's Alpha Values at .70." Advances in Methods and Practices in Psychological Science, 8(1), 2025.
- World Metrics. "Reliability and Validity Statistics: Market Data Report 2025."
- Bogdan, P.C. "One Decade Into the Replication Crisis, How Have Psychological Results Changed?" Advances in Methods and Practices in Psychological Science, 8(1), 2025.
- Hallgren, K.A. "Considerations when designing, analyzing, and reporting reliability studies." BMC Medical Research Methodology, 25(68), 2025.
- Flake, J.K. & Fried, E.I. "Measurement Schmeasurement: Questionable Measurement Practices and How to Avoid Them." Advances in Methods and Practices in Psychological Science, 3(4), 2020.



